Introducing HanziCraft
Today, I introduce HanziCraft. It’s a project that I’ve been working on for some time now. It started with my thesis, where I needed to easily decompose Chinese characters for my research. I then found data and wrote a little decomposition tool for myself. This was called HanziJS. However, as time went on I realized I wanted more than just decomposition data. Why not create a site that pushes the value of Chinese character dictionaries to a new level?
What I mean by this, is that when I want to look up a Chinese character to learn (especially for something like the Chinese character challenge) I want as much information possible to help me learn that character, especially regarding how some radicals affect your reading on a sub-conscious level.
Questions that come up:
- What are the radicals?
- How does the decomposition traverse itself?
- Is there any phonetic information available?
- Does this character have many definitions? How is it pronounced?
- Now that I know more of the character, where does it fit into vocabulary?
- Is the vocabulary useful?
Those questions are the ones that I want answered when it comes to a Chinese character dictionary. I have found some sites that can serve such a goal, but they are either badly designed, don’t have all the answers and/or is in Chinese only.
What will become of HanziJS?
HanziJS is the code behind HanziCraft. It is an open-source module for Node.js. This is the backbone. HanziCraft is thus an application of the code itself (hopefully other people will create their own apps with the HanziJS code in the future!).
If you are a coder, go check out the github repo. There’s quite a lot of updates to it, as well as quite a bit of refactoring (thanks Dusan!). I’m busy writing proper documentation for it.
Introducing HanziCraft
I think the best you can do, is to just visit the site and see for yourself. Check the info for the character 魔 for instance:
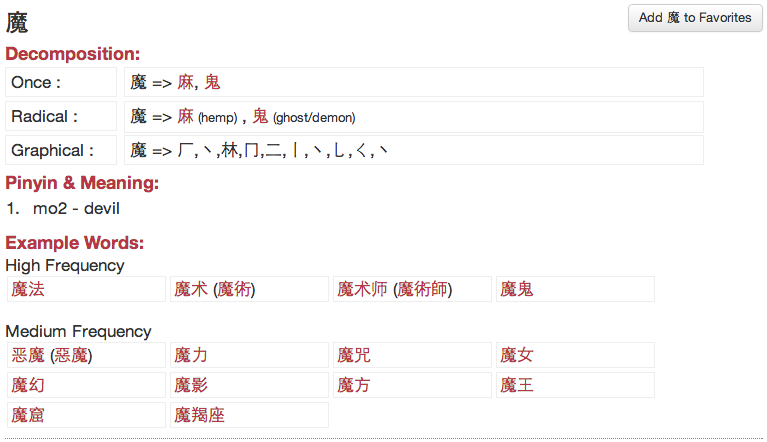
Delicious juicy info!
If you want to know how I determine the example words, find the question in the FAQ.
P.S. - If you see any question marks or blocks, then you need to install the proper font to display all the components. Download the font here.
Beta
HanziCraft is now in it’s beta phase. There will be bugs! But with this beta phase, you’ll get a discounted premium account. What do you get with a premium account? (Besides my eternal gratitude)
- Lookup more than one character at a time
- Favorite lists
- Your own user dashboard (currently showing your lookup history. I will implement character analytics in the future)
- No ads
- All future premium features forever free.
- AND Less hassle in learning Chinese characters (and who doesn't want that!?)
Future Features
I’ve got quite a bit more features planned for HanziCraft. Some premium & some free. Here’s what to expect:
- Display potential phonetic information in the radicals
- Display similar characters based on components (if a character shares more than 50% similar components)
- Text Analysis (this will be a premium feature that will take a group of characters, perhaps an article and compute what you need to know from the text. This will include unique characters, unique radicals, frequency counts and other cool information)
With all this being said, I think HanziCraft is a tool that I created for myself, mainly because I had trouble finding all the useful information I needed. I was eager, like a crazy addict, trying to find the information I craved, and after countless hours HanziCraft was born.
I hope HanziCraft becomes your goto Chinese character dictionary. I’m building it to be my own goto dictionary, so tell me, what do you need to make it the ultimate Chinese character dictionary? I’ll try my best to implement the features you need. Happy learning!