Phonetic Sets in Chinese Characters
You might have noticed that a few weeks ago I added a feature to HanziCraft that automatically tries to find pronunciation clues in each character. Using this tool, I decided to create phonetic sets using the 6800 most frequent Chinese characters.
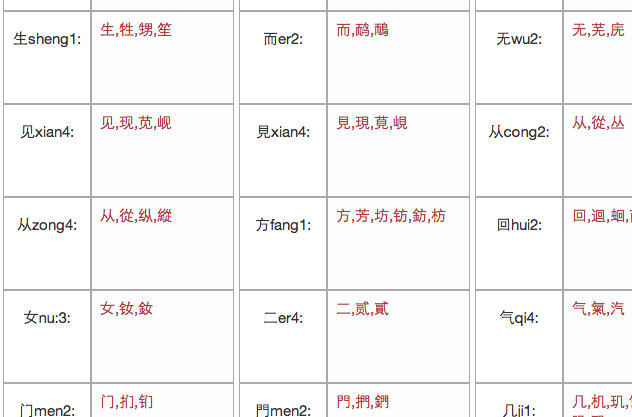
What is a phonetic set?
I quote from HanziCraft
A phonetic set is a list of characters where a component produces the same pronunciation clue towards each character. For instance, the component 马, which is pronounced as 'ma3', can be found in these characters: 吗,玛,码,蚂,犸. They all have the same pronunciation 'ma3'.
I decided to generate two lists. One where components have the exact same pronunciation as the character, and two, where the component has the same syllable but differs on tone.
You can see both lists here.
Interesting Findings?
令(ling2) is awesome! Just look at this list of all the characters that have the exact same pronunciation:
零,玲,铃,鈴,龄,齡,伶,翎,聆,羚,苓,蛉,呤,泠,囹,瓴,鸰,鴒,舲
And this one where it includes all the characters with 令, but with different tones.
领,領,零,玲,铃,鈴,龄,齡,岭,伶,翎,聆,羚,苓,蛉,呤,泠,囹,瓴,鸰,鴒,舲
You’ll see some characters overlap, because some characters have multiple pronunciations.
Combinality
As I mention on the page, combinality is still another variable to consider when you look at these lists. How trustworthy is a component in providing those clues to the character?
Read my post on sub-conscious variables in Chinese characters for more info. This is a variable that HanziCraft is working on trying to find. It’s not that hard, but just needs some more coding.